Given their robust performance, demonstrated ability to mimic synoptic-scale kinematic and thermodynamic properties, and ongoing rapid development, data-driven models will play an integral role in the present and future of numerical weather prediction. Given that, it is fair to ask: how will and how should data-driven models be tested and evaluated? The DTC’s Science Advisory Board began to broach these questions at its Fall 2023 meeting, and given continued advances in data-driven modeling since then, these questions are even more timely now. While I don’t claim to have the answers to these important questions, I would like to share a little about what I see are the current similarities and differences in testing and evaluating these models.
Testing innovations for traditional numerical weather prediction models typically involves making one or more code changes to attempt to address a known deficiency, then running a series of increasingly complex tests (e.g., physics simulator to single-column model to two- and then fully three-dimensional models) to assess whether the changes are having the desired effect. Doing so requires a modest computational expense that is tractable for many individual researchers and research groups. This process also holds for hybrid dynamical/data-driven models, in which the specific artificial-intelligence emulators are trained separately from the rest of the model, and represents a potential new capacity for the DTC’s Common Community Physics Package.
Testing fully data-driven models is quite different. Even as these models are informed by many architectural and hyperparameter choices, testing changes to these attributes currently requires retraining the entire model, which carries a significant computational expense (many dedicated graphics and/or tensor processing units for several days or weeks) that is not presently tractable for most researchers. Thus, until these computational resources – ideally complemented by community frameworks for developing, testing, and evaluating data-driven models at scale – become more widely available, testing innovations to data-driven models may primarily be the domain of well-resourced teams. In the interim, testing efforts may emphasize tuning pretrained models for specific prediction tasks, which typically carries less computational expense.
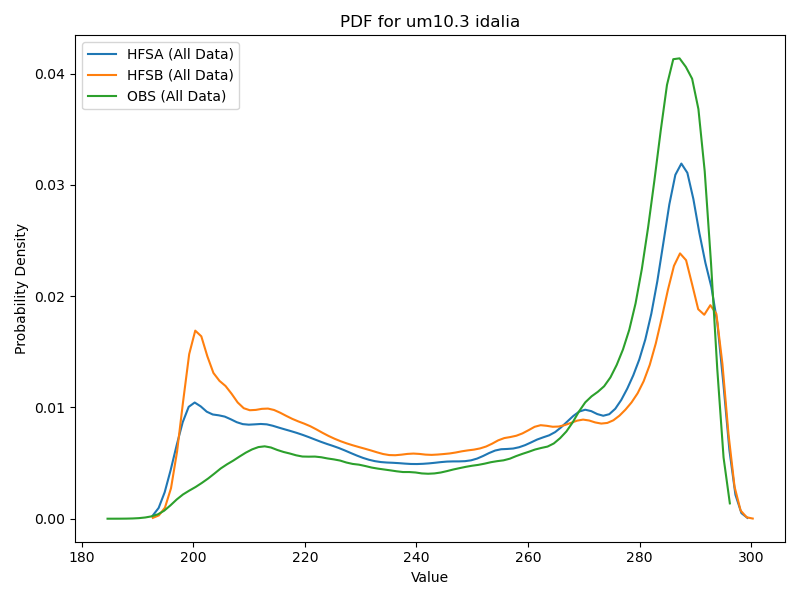
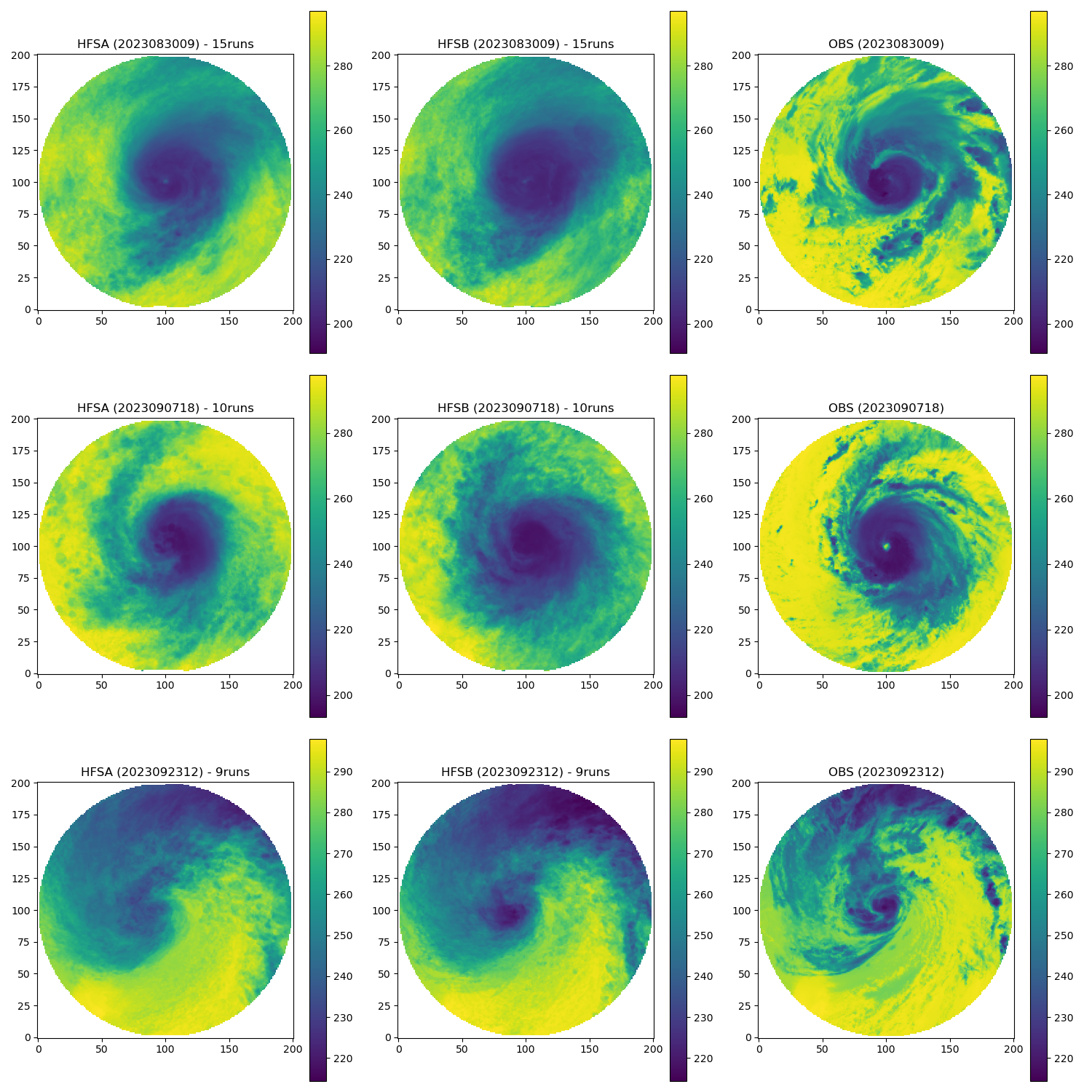
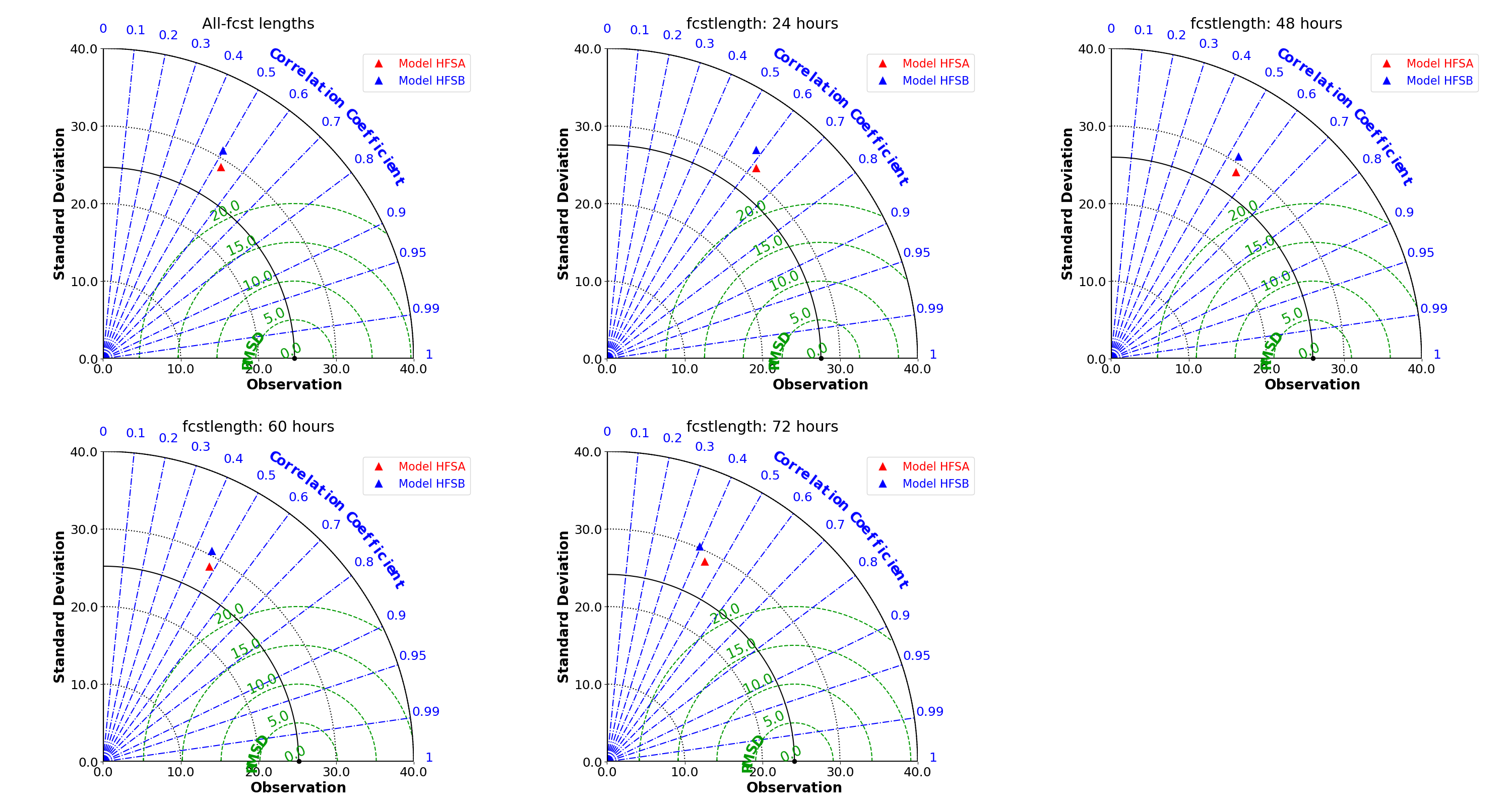
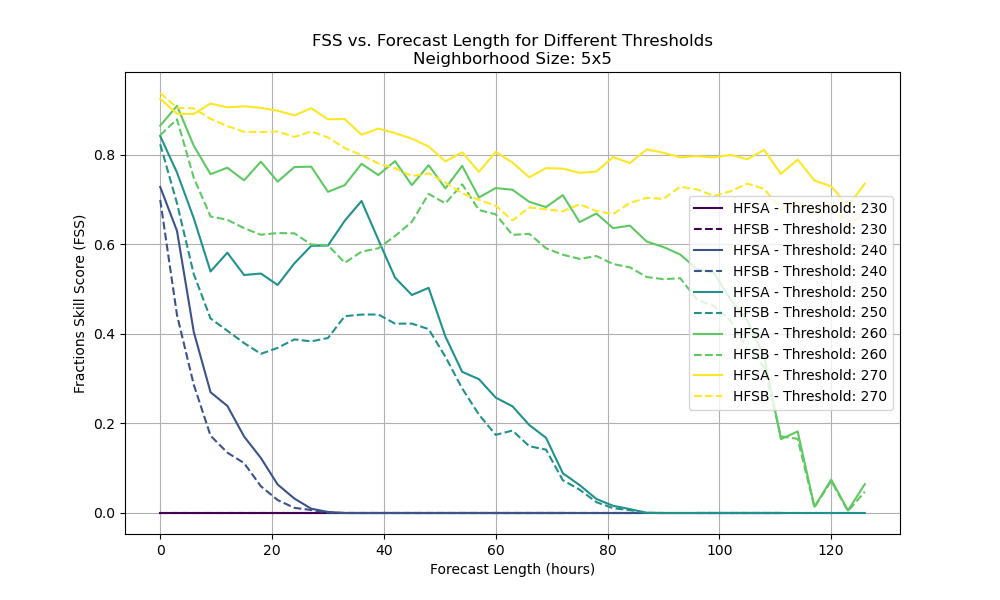
There may be fewer changes in how models are evaluated, however. Evaluating traditional numerical weather prediction models typically involves process-oriented diagnoses and forecast-verification activities to assess whether their solutions are physically realistic and quantify whether their solutions are improved relative to a suitable baseline. Yet, although data-driven models are presently limited in their outputs (e.g., these models do not currently attempt to mimic physical-process tendencies and the temporal frequency of their outputs is limited by the specific prediction interval for which the models are trained), their evaluation looks much the same as for traditional models. This is exemplified by idealized evaluations of Pangu-Weather by Greg Hakim and Sanjit Masanam and a case-study evaluation for Storm Ciarán by Andrew Charlton-Perez and collaborators.
There are two noteworthy practical differences in evaluating traditional versus data-driven weather prediction models, however. First, as data-driven models bring trivial computational expense compared to traditional models, it is far easier to generate large datasets over a wide range of cases or conditions to robustly evaluate data-driven models. It also makes case-study analyses accessible to a wider range of researchers, particularly at under-resourced institutions and in developing countries. Second, although similar metrics are currently being used to verify both types of models, parallel verification infrastructures have become established for traditional versus data-driven models. An example is given by the DTC’s METplus verification framework, which underpins several modeling centers’ verification systems, and Google’s Python-based WeatherBench 2 suite for verifying data-driven models. Whereas the range of applications is currently far greater for METplus, WeatherBench 2 facilitates fully Python-based verification workflows against cloud-based gridded analysis datasets. Consequently, I believe that the broader weather-prediction community would benefit from closer collaborations between the traditional and data-driven weather modeling communities, such as hosting workshops, visitor projects, and informal discussions, to ensure that both communities can best learn from the other’s expertise and experiences.