${MET_BUILD_BASE}/bin/gen_vx_mask \
data/sample_fcst/2005080700/wrfprs_ruc13_12.tm00_G212 \
data/sample_fcst/2009123112/arw-fer-gep1/d01_2009123112_02400.grib \
mask.nc -name MY_MASK
- The polyline mask for the different grids is producing slightly different results and the differences lie along the boundary of the mask.
- There are some missing data values somewhere in the forecast and observations causing slightly different matched pairs.
- Use the regrid_data_plane tool to regrid 2m temperature to a smaller domain centered on China:
- Run plot_data_plane to plot with the default map background:
- Re-run but pointing only to the admin_China_data:
In this example the dimension of the grid is 37x37. Thus, up to 1369 matched pairs are possible. However, if the forecast or observation contains bad data at a point, that matched pair is not included in the calculations. Use the ncview tool to look at an example netCDF file. If the forecast field contains missing data around the edge of the domain, then that is a reason there may be 992 matched pairs instead of 1369.
- Dimensions should be named "lat" and "lon"
- The "lat" and "lon" variable are **NOT** required
- Gridded variables (e.g. APCP_12) must use the "lat" and "lon" dimensions
- Gridded variables should include the attributes listed in the example (for timing info, only the init_time_ut, valid_time_ut, and accum_time_sec are actually used. "ut" stands for unix time, the number of seconds since Jan 1, 1970).
- Global attributes should include the grid/projection information.
- The input field (fcst.grb) defines the domain for the mask.
- Since we're doing data masking and the data we want lives in fcst.grb, we pass it in again as the mask_file.
- Lastly "-mask_field" specifies the data we want from the mask file and "-thresh" specifies the event threshold.
- Do data masking (-type data)
- Read the NetCDF variable named "TMP_Z2" from the input file (tmp_mask.nc)
- Define the mask by reading 6-hour precip from the mask file (fcst.grb) and looking for values > 0 (-mask_field)
- Apply intersection logic when combining the "input" value with the "mask" value (-insersection).
- Name the output NetCDF variable as "FREEZING_PRECIP" (-name). This is totally optional, but convenient.
It is possible to compute the fractions skill score for comparing forecast and observed thunderstorms. When computing FSS, first threshold the fields to define events and non-events. Then look at successively larger and larger areas around each grid point to see how the forecast event frequency compares to the observed event frequency. Applying this to thunderstorms would be reasonable.
Also, applying it to rainfall (and monsoons) would be fine. Keep in mind that Grid-Stat is the tool that computes FSS. Grid-Stat will need to be run once for each evaluation time. As an example, to evaluating once per day, run Grid-Stat 122 times for the 122 days of a monsoon season. This will result in 122 FSS values. These can be viewed as a time series, or the Stat-Analysis tool could be used to aggregate them together into a single FSS value, like this:
stat_analysis -job aggregate -line_type NBRCNT \
-lookin out/grid_stat
Be sure to pick thresholds (e.g. for the thunderstorms and monsoons) that capture the "events" that are of interest in studying.
Setting up the Grid-Stat config file to read a netcdf file generated by a MET tool:
fcst = { field = [
{ name = "HGT_P500"; level = [ "(*,*)" ]; } ]; }
Do not use numbers, such as "(181,360)", please use "(*,*)" instead. NetCDF variables can have an arbitrary number of dimensions. For example, many variables in the NetCDF output WRF have 4 dimensions... time, vertical level, lat, and lon. That cryptic level string with *'s in it tells MET which 2D slice of lat/lon data to process. For a WRF file "(3, 5, *, *)" would say get data from the 3rd time dimension and 5th vertical level.
However the NetCDF files that the MET tools generate are much simpler, and only contain 2 dimensional variables. So using "(*,*)" suffices.
An example of verifying a probability of precipitation field is included in the test scripts distributed with the MET tarball. Please take a look at
${MET_BUILD_BASE}/scripts/test_grid_stat.sh
The second call to grid_stat is used to evaluate probability of precip using this config file:
${MET_BUILD_BASE}/scripts/config/GridStatConfig_POP_12
Note in there the following...
"prob = TRUE;" tells MET to interpret this data a probability field.
"cat_thresh = [ >=0.0, >=0.1, >=0.2, >=0.3, >=0.4, >=0.5, >=0.6, >=0.7, >=0.8, >=0.9]; "
Here the thresholds are used to fully partition the probability space from 0 to 1. Note that if the probability data contains values from 0 to 100, MET automatically divides by 100 to rescale to the 0 to 1 range.
Run Grid-Stat using the following commands and the attached config file
mkdir out
${MET_BUILD_BASE}/bin/grid_stat \
gfs_4_20160220_0000_012.grb2 \
ST4.2016022012.06h \
GridStatConfig \
-outdir out
Note the following two sections of the Grid-Stat config file:
regrid = {
to_grid = OBS;
vld_thresh = 0.5;
method = BUDGET;
width = 2;
}
This tells Grid-Stat to do verification on the "observation" grid. Grid-Stat reads the GFS and Stage4 data and then automatically regrids the GFS data to the Stage4 domain using budget interpolation. Use "FCST" to verify on the forecast domain. And use either a named grid or a grid specification string to regrid both the forecast and observation to a common grid. For example, to_grid = "G212"; will regrid both to NCEP Grid 212 before comparing them.
mask = { grid = [ "FULL" ];
poly = [ "MET_BASE/poly/CONUS.poly" ]; }
This will compute statistics over the FULL model domain as well as the CONUS masking area.
To demonstrate that Grid-Stat worked as expected, run the following commands to plot its NetCDF matched pairs output file:
${MET_BUILD_BASE}/bin/plot_data_plane \
out/grid_stat_120000L_20160220_120000V_pairs.nc \
out/DIFF_APCP_06_A06_APCP_06_A06_CONUS.ps \
'name="DIFF_APCP_06_A06_APCP_06_A06_CONUS"; level="(*,*)";'
Examine the resulting plot of that difference field.
Lastly, there is another option for defining that masking region. Rather than passing the ascii CONUS.poly file to grid_stat, run the gen_vx_mask tool and pass the NetCDF output of that tool to grid_stat. The advantage to gen_vx_mask is that it will make grid_stat run a bit faster. It can be used to construct much more complex masking areas.
There is an example of verifying probabilities in the test scripts included with the MET release. Take a look in:
${MET_BUILD_BASE}/scripts/config/GridStatConfig_POP_12
The config file should look something like this...
fcst = {
wind_thresh = [ NA ];
field = [
{
name = "LCDC";
level = [ "L0" ];
prob = TRUE;
cat_thresh = [ >=0.0, >=0.1, >=0.2, >=0.3, >=0.4, >=0.5, >=0.6, >=0.7, >=0.8, >=0.9];
}
];
};
obs = {
wind_thresh = [ NA ];
field = [
{
name = "WIND";
level = [ "Z2" ];
cat_thresh = [ >=34 ];
}
];
};
Without seeing how it's encoded in the GRIB file, it is unclear how to handle “name” in the forecast section. The PROB flag is set to TRUE to tell grid_stat to process this as probability data. The cat_thresh is set to partition the probability values between 0 and 1.
This case is evaluating a forecast probability of wind speed exceeding 34kts, and likely comparing it against the wind speed values. The observed cat_thresh is set to >=34 to be consistent with with the forecast probability definition.
You'd like to apply one mask to the forecast field and a *different* mask to the observation field. However, you can't define different masks for the forecast and observation fields. MODE only lets you define a single mask (a masking grid or polyline) and then you choose whether your want to apply it to the FCST, OBS, or BOTH of them.
Nonetheless, there is a way you can accomplish this logic using the gen_vx_mask tool. You run it once to pre-process the forecast field and a second time to pre-process the observation field. And then pass those output files to MODE.
Below is an example using sample data that is included with the MET release tarball to illustrate... using met. This will read 3-hour precip and 2-meter temperature, and resetts the precip at any grid point where the temperature is less than 290 K to a value of 0:
{MET_BUILD_BASE}/bin/gen_vx_mask \
data/sample_fcst/2005080700/wrfprs_ruc13_12.tm00_G212 \
data/sample_fcst/2005080700/wrfprs_ruc13_12.tm00_G212 \
APCP_03_where_2m_TMPge290.nc \
-type data \
-input_field 'name="APCP"; level="A3";' \
-mask_field 'name="TMP"; level="Z2";' \
-thresh 'lt290&&ne-9999' -v 4 -value 0
So this is a bit confusing. Here's what is happening:
- The first argument is the input file which defines the grid.
- The second argument is used to define the masking region... and since I'm reading data from the same input file, I've listed that file twice.
- The third argument is the output file name.
- The type of masking is "data" masking where we read a 2D field of data and apply a threshold.
- By default, gen_vx_mask initializes each grid point to a value of 0. Specifying "-input_field" tells it to initialize each grid point to the value of that field (in my example 3-hour precip).
- The "-mask_field" option defines the data field that should be thresholded.
- The "-thresh" option defines the threshold to be applied.
- The "-value" option tells it what "mask" value to write to the output... and I've chosen 0.
The example threshold is less than 290 and not -9999 (which is MET's internal missing data value). So any grid point where the 2 meter temperature is less than 290 K and is not bad data will be replaced by a value of 0.
To more easily demonstrate this, I changed to using "-value 10" and ran the output through plot_data_plane:
{MET_BUILD_BASE}/bin/plot_data_plane \
APCP_03_where_2m_TMPge290.nc APCP_03_where_2m_TMPge290.ps \
'name="data_mask"; level="(*,*)";'
In the resulting plot, anywhere you see the pink value of 10, that's where gen_vx_mask has masked out the grid point.
Problems configuring a good set of options for pcp_combine. Run the command in the following way:
#!/bin/sh
/usr/local/met/bin/pcp_combine -add \
rap_130_20160128_1000_003.grb2 1 \
rap_130_20160128_1100_003.grb2 1 \
rap_test_add.nc \
-field 'name="ACPCP"; level="A1";' \
-v 5
This indicates that the name is "ACPCP" and the level is "A1" or a 1- hour accumulation.
Run the MET pcp_combine tool to put the NAM data into 3-hourly accumulations.
0-3 hour accumulation is already in the 03UTC file. Run this file through pcp_combine as a pass-through to put it into NetCDF format:
[MET_BUILD_BASE}/pcp_combine -add 03_file.grb 03 APCP_00_03.nc
3-6 hour accumulation. Subtract 0-6 and 0-3 accumulations:
[MET_BUILD_BASE}/pcp_combine -subtract 06_file.grb 06 03_file.grb 03 APCP_03_06.nc
6-9 hour accumulation. Subtract 0-9 and 0-6 accumulations:
[MET_BUILD_BASE}/pcp_combine -subtract 09_file.grb 09 06_file.grb 06 APCP_06_09.nc
9-12 hour accumulation. Subtract 0-12 and 0-9 accumulations:
[MET_BUILD_BASE}/pcp_combine -subtract 12_file.grb 12 09_file.grb 09 APCP_09_12.nc
12-15 hour accumulation. Just run as a pass-through again:
[MET_BUILD_BASE}/pcp_combine -add 15_file.grb 03 APCP_12_15.nc
15-18 hour accumulation. Subtract 12-18 and 12-15 accumulations:
[MET_BUILD_BASE}/pcp_combine -subtract 18_file.grb 06 15_file.grb 03 APCP_15_18.nc
Run the 0-3 and 12-15 through pcp_combine even though they already have the 3-hour accumulation. That way, all of the NAM files will be in the same file format, and can use the same configuration file settings for the other MET tools (grid_stat, mode, etc.). If the NAM files are a mix of GRIB and NetCDF, the logic would need to be a bit more complicated.
The "-sum" command assumes the same initialization time. Use the "-add" option instead.
${MET_BUILD_BASE}/bin/pcp_combine -add \
WRFPRS_1997-06-03_APCP_A12.nc 'name="APCP_12"; level="(*,*)";' \
WRFPRS_d01_1997-06-04_00_APCP_A12.grb 12 \
Sum.nc
For the first file, list the file name followed by a config string describing the field to use from the NetCDF file. For the second file, list the file name followed by the accumulation interval to use (12 for 12 hours).
Here is a small excerpt from the pcp_combine usage statement:
Note: For “-add” and "-subtract”, the accumulation intervals may be substituted with config file strings. For that first file, we replaced the accumulation interval with a Config file string.
Here are 3 commands you could use to plot these data files:
${MET_BUILD_BASE}/bin/plot_data_plane WRFPRS_1997-06-03_APCP_A12.nc \
WRFPRS_1997-06-03_APCP_A12.ps 'name="APCP_12"; level="(*,*)";'
${MET_BUILD_BASE}/bin/plot_data_plane WRFPRS_d01_1997-06-04_00_APCP_A12.grb \
WRFPRS_d01_1997-06-04_00_APCP_A12.ps 'name="APCP" level="A12";'
${MET_BUILD_BASE}/bin/plot_data_plane sum.nc sum.ps 'name="APCP_24"; level="(*,*)";'
Typically, accumulated precipitation is stored in GRIB files using an accumulation interval with a "time range" indicator value of 4. Here is a description of the different time range indicator values and meanings: http://www.nco.ncep.noaa.gov/pmb/docs/on388/table5.html
For example, take a look at the APCP in the GRIB files included in the MET tar ball:
wgrib ${MET_BUILD_BASE}/data/sample_fcst/2005080700/wrfprs_ruc13_12.tm00_G212 | grep APCP
1:0:d=05080700:APCP:kpds5=61:kpds6=1:kpds7=0:TR=4:P1=0: \
P2=12:TimeU=1:sfc:0- 12hr acc:NAve=0
2:31408:d=05080700:APCP:kpds5=61:kpds6=1:kpds7=0:TR=4: \
P1=9:P2=12:TimeU=1:sfc:9- 12hr acc:NAve=0
The "TR=4" indicates that these records contain an accumulation between times P1 and P2. In the first record, the precip is accumulated between 0 and 12 hours. In the second record, the precip is accumulated between 9 and 12 hours.
However, the GRIB data uses a time range indicator of 5, not 4.
wgrib rmf_gra_2016040600.24 | grep APCP
291:28360360:d=16040600:APCP:kpds5=61:kpds6=1:kpds7=0: \
TR=5:P1=0:P2=24:TimeU=1:sfc:0-24hr diff:NAve=0
pcp_combine is looking in "rmf_gra_2016040600.24" for a 24 hour *accumulation*, but since the time range indicator is no 4, it doesn't find a match.
If possible switch the time range indicator to 4 on the GRIB files. If this is not possible, there is another workaround. Instead of telling pcp_combine to look for a particular accumulation interval, give it a more complete description of the chosen field to use from each file. Here is an example:
pcp_combine -add rmf_gra_2016040600.24 'name="APCP"; level="L0-24";' \
rmf_gra_2016040600_APCP_00_24.nc
The resulting file should have the accumulation listed at 24h rather than 0-24.
MET can read gridded data in GRIB1, GRIB2, or 3 different flavors of NetCDF:
- The "internal" NetCDF format that looks like the output of the pcp_combine tool.
- CF-compliant NetCDF3 files.
- The output of the wrf_interp utility.
If there are the NetCDF output from WRF, use UPP to post-process it. It does not need to be "lat-lon"... it can be post-processed to whatever projection is needed..
There is in general no easy way to convert NetCDF to GRIB. If the NetCDF data is self generated, make it look like the NetCDF output from pcp_combine, or preferably, make it CF-compliant.
Looking at the accumulation interval of the precipitation data in the WRF output files from UPP, use the "wgrib" utility to dump out that sort of information:
wgrib wrfprs_d01.02
wgrib wrfprs_d01.03
The question is whether the output actually contains 1-hourly accumulated precip, or does it contain runtime accumulation. Runtime accumulation means that the 6-hour wrf file contains 0 to 6 hours of precip; the 7- hour file contains 0 to 7 hours of precip; and so on. The precip values just accumulate over the course of the entire model integration.
The default for WRF-ARW is runtime accumulation. So if WRF-ARW is running and the output bucket interval wasn’t specifically changed, then that's very likely.
If that is the case, you can change these values to interval accumulations. Use the pcp_combine "-subtract" option instead of "-sum". Suppose the 6 hours of precip between the 6hr and 12hr forecasts is wanted. Run the following:
pcp_combine -subtract wrfprs_d01.12 12 \
wrfprs_d01.06 06 apcp_06_to_12.nc
That says... get 12 hours of precip from the first file and 6 hours from the second file and subtract them.
The pcp_combine tool is typically used to modify the accumulation interval of precipitation amounts in model and/or analysis datasets. For example, when verifying model output in GRIB format containing runtime accumulations of precipitation, run the pcp_combine -subtract option every 6 hours to create 6-hourly precipitation amounts. In this example, it is not really necessary to run pcp_combine on the 6-hour GRIB forecast file since the model output already contains the 0 to 6 hour accumulation. However, the output of pcp_combine is typically passed to point_stat, grid_stat, or mode for verification. Having the 6-hour forecast in GRIB format and all other forecast hours in NetCDF format (output of pcp_combine) makes the logic for configuring the other MET tools messy. To make the configuration consist for all forecast hours, one option is to choose to run pcp_combine as a pass-through to simply reformat from GRIB to NetCDF. Listed below is an example of passing a single record to the pcp_combine -add option to do the reformatting:
$MET_BUILD/bin/pcp_combine -add forecast_F06.grb \
'name="APCP"; level="A6";' \
forecast_APCP_06_F06.nc -name APCP_06
Reformatting from GRIB to NetCDF may be done for any other reason the user may have. For example, the -name option can be used to define the NetCDF output variable name. Presuming this file is then passed to another MET tool, the new variable name (CompositeReflectivity) will appear in the output of downstream tools:
$MET_BUILD/bin/pcp_combine -add forecast.grb \
'name="REFC"; level="L0"; GRIB1_ptv=129; lead_time="120000";' \
forecast.nc -name CompositeReflectivity
To run a project faster, the “-pcprx” option may be used to narrow the search down to whatever regular expression you provide. Here are a two examples:
# Only using Stage IV data (ST4)
${MET_BUILD_BASE}/bin/pcp_combine -sum 00000000_000000 06 \
20161015_18 12 ST4.2016101518.APCP_12_SUM.nc -pcprx "ST4.*.06h"
# Specify that files starting with pgbq[number][number]
be used:
[MET_BUILD_BASE]/bin/pcp_combine \
-sum 20160221_18 06 20160222_18 24 \
gfs_APCP_24_20160221_18_F00_F24.nc \
-pcpdir /scratch4/BMC/shout/ptmp/Andrew.Kren/pre2016c3_corr/temp \
-pcprx 'pgbq[0-9][0-9].gfs.2016022118' -v 3
Here is an incorrect example of running pcp_combine with sub-hourly accumulation intervals:
pcp_combine -subtract forecast.grb 0055 \
forecast2.grb 0005 forecast.nc -field APCP
The time signature is entered incorrectly. Let’s assume that "0055" meant 0 hours and 55 minutes and "0005" meant 0 hours and 5 minutes.
Looking at the usage statement for pcp_combine (just type pcp_combine with no arguments): "accum1" indicates the accumulation interval to be used from in_file1 in HH[MMSS] format (required).
The time format listed "HH[MMSS]" means specifying hours or hours/minutes/seconds. The incorrect example is using hours/minutes.
Below is the correct example. Add the seconds to the end of the time strings, like this:
pcp_combine -subtract forecast.grb 005500 \
forecast2.grb 000500 forecast.nc -field APCP
Run wgrib on the data files and the output is listed below:
279:503477484:d=15062313:APCP:kpds5=61:kpds6=1:kpds7=0:TR= 10:P1=3:P2=247:TimeU=0:sfc:1015min \
fcst:NAve=0 \
279:507900854:d=15062313:APCP:kpds5=61:kpds6=1:kpds7=0:TR= 10:P1=3:P2=197:TimeU=0:sfc:965min \
fcst:NAve=0
Notice the output which says "TR=10". TR means time range indicator and a value of 10 means that the level information contains an instantaneous forecast time, not an accumulation interval.
Here's a table describing the TR values: http://www.nco.ncep.noaa.gov/pmb/docs/on388/table5.html
The default logic for pcp_combine is to look for GRIB code 61 (i.e. APCP) defined with an accumulation interval (TR = 4). Since the data doesn't meet that criteria, the default logic of pcp_combine won't work. The arguments need to be more specific to tell pcp_combine exactly what to do.
${MET_BUILD_BASE}/bin/pcp_combine -subtract \
forecast.grb 'name="APCP"; level="L0"; lead_time="165500";' \
forecast2.grb 'name="APCP"; level="L0"; lead_time="160500";' \
forecast.nc -name APCP_A005000
Some things to point out here:
- Notice in the wgrib output that the forecast times are 1015 min and 965 min. In HHMMSS format, that's "165500" and "160500".
- An accumulation interval can’t be specified since the data isn't stored that way. Instead, use a config file string to describe the data to use.
- The config file string specifies a "name" (APCP) and "level" string. APCP is defined at the surface, so a level value of 0 (L0) was specified.
- Technically, the "lead_time" doesn’t need to be specified at all, pcp_combine would find the single APCP record in each input GRIB file and use them. But just in case, the lead_time option was included to be extra certain to get exactly the data that is needed.
- The default output variable name pcp_combine would write would be "APCP_L0". However, to indicate that its a 50-minute "accumulation interval" use a different output variable name (APCP_A005000). Of course any string name is possible.... Maybe "Precip50Minutes" or "RAIN50". But whatever string is chosen will be used in the Grid-Stat, Point-Stat, or MODE config file to tell that tool what variable to process.
Here is an example of using pcp_combine to put GFS into 24- hour intervals for comparison against 24-hourly StageIV precipitation with GFS data through the pcp_combine tool. Be aware that the 24-hour StageIV data is defined as an accumulation from 12Z on one day to 12Z on the next day: http://www.emc.ncep.noaa.gov/mmb/ylin/pcpanl/stage4/
Therefore, only the 24-hour StageIV data can be used to evaluate 12Z to 12Z accumulations from the model. Alternatively, the 6- hour StageIV accumulations could be used to evaluate any 24 hour accumulation from the model. For the latter, run the 6-hour StageIV files through pcp_combine to generate the desired 24-hour accumulation.
Here is an example. Run pcp_combine to compute 24-hour accumulations for GFS. In this example, process the 20150220 00Z initialization of GFS.
${MET_BUILD_BASE}/bin/pcp_combine \
-sum 20150220_00 06 20150221_00 24 \
gfs_APCP_24_20150220_00_F00_F24.nc \
-pcprx "gfs_4_20150220_00.*grb2" \
-pcpdir /d1/model_data/20150220
pcp_combine is looking in the /d1/SBU/GFS/model_data/20150220 directory at files which match this regular expression "gfs_4_20150220_00.*grb2". That directory contains data for 00, 06, 12, and 18 hour initializations, but the "-pcprx" option narrows the search down to the 00 hour initialization which makes it run faster. It inspects all the matching files, looking for 6-hour APCP data to sum up to a 24-hour accumulation valid at 20150221_00. This results in a 24-hour accumulation between forecast hours 0 and 24.
The following command will compute the 24-hour accumulation between forecast hours 12 and 36:
${MET_BUILD_BASE}/bin/pcp_combine \
-sum 20150220_00 06 20150221_12 24 \
gfs_APCP_24_20150220_00_F12_F36.nc \
-pcprx "gfs_4_20150220_00.*grb2" \
-pcpdir /d1/model_data/20150220
The "-sum" command is meant to make things easier by searching the directory. But instead of using "-sum", another option would be the "- add" command. Explicitly list the 4 files that need to be extracted from the 6-hour APCP and add them up to 24. In the directory structure, the previous "-sum" job could be rewritten with "-add" like this:
${MET_BUILD_BASE}/bin/pcp_combine -add \
/d1/model_data/20150220/gfs_4_20150220_0000_018.grb2 06 \
/d1/model_data/20150220/gfs_4_20150220_0000_024.grb2 06 \
/d1/model_data/20150220/gfs_4_20150220_0000_030.grb2 06 \
/d1/model_data/20150220/gfs_4_20150220_0000_036.grb2 06 \
gfs_APCP_24_20150220_00_F12_F36_add_option.nc
This example explicitly tells pcp_combine which files to read and what accumulation interval (6 hours) to extract from them. The resulting output should be identical to the output of the "-sum" command.
To run a project faster, -pcprx is an option.
${MET_BUILD_BASE}/bin/pcp_combine \
-sum 20160221_18 06 20160222_18 24 \
gfs_APCP_24_20160221_18_F00_F24.nc \
-pcpdir model_out/temp \
-pcprx 'pgbq[0-9][0-9].gfs.2016022118' -v 3
But this only matches 2-digit forecast hours.
The "-add" command could be used instead of the “-sum” command:
${MET_BUILD_BASE}/bin/pcp_combine -add \
model_out/temp/pgbq06.gfs.2016022118 06 \
model_out/temp/pgbq12.gfs.2016022118 06 \
model_out/temp/pgbq18.gfs.2016022118 06 \
model_out/temp/pgbq24.gfs.2016022118 06 \
gfs_APCP_24_20160221_18_F00_F24_ADD.nc
The -sum and -add options both do the same thing... it's just that '- sum' finds the files more quickly. This could also be accomplished by using a calling script.
The gen_vx_mask tool is successfully writing a NetCDF file, but the pcp_combine tool errors out when trying to write a NetCDF file:
ERROR : write_netcdf() -> error with pcp_var->put()
The question is why? Let's check to see if the call to gen_vx_mask actually did create good output. Try running the following command from the top-level ${MET_BUILD_BASE} directory:
bin/plot_data_plane \
out/gen_vx_mask/CONUS_poly.nc \
out/gen_vx_mask/CONUS_poly.ps \
'name="CONUS"; level="(*,*)";'
And then view that postscript output file, using something like "gv" for ghostview:
gv out/gen_vx_mask/CONUS_poly.ps
These files are in GRIB2 format, but they’ve named them using the ".grib" suffix. When MET reads Gridded data files, it must determine the type of file it's reading. The first thing it checks is the suffix of the file. The following are all interpreted as GRIB1: .grib, .grb, and .gb. While these mean GRIB2: .grib2, .grb2, and .gb2.
There are 2 choices. Rename the files to use a GRIB2 suffix or keep them named this way and explicitly tell MET to interpret them as GRIB2 using the "file_type" configuration option.
The examples below use the plot_data_plane tool to plot the data. Set
"file_type = GRIB2;".
To keep them named this way, add "file_type = GRIB2;" to all the MET configuration files (i.e. Grid-Stat, MODE, and so on) that you use:
{MET_BASE}/bin/plot_data_plane \
test_2.5_prog.grib \
test_2.5_prog.ps \
'name="TSTM"; level="A0"; file_type=GRIB2;' \
-plot_range 0 100
When trying to get MET to read a particular gridded data file, use the plot_data_plane tool to test it out.
Making sure MET can read GRIB2 data. Plot the data from that GRIB2 file by running:
${MET_BUILD_BASE}/bin/plot_data_plane LTIA98_KWBR_201305180600.grb2 tmp_z2.ps 'name="TMP"; level="R2";
"R2" tells MET to plot record number 2. Record numbers 1 and 2 both contain temperature data and 2-meters. Here's some wgrib2 output:
1:0:d=2013051806:TMP:2 m above ground:anl:analysis/forecast error 2:3323062:d=2013051806:TMP:2 m above ground:anl:
Here's how to compute and verify wind speed using MET. Good news, MET already includes logic for deriving wind speed on the fly. The GRIB abbreviation for wind speed is WIND. To request WIND from a GRIB1 or GRIB2 file, MET first checks to see if it already exists in the current file. If so, it'll use it as is. If not, it'll search for the corresponding U and V records and derive wind speed to use on the fly.
In this example the RTMA file is named rtma.grb2 and the UPP file is named wrf.grb, please try running the following commands to plot wind speed:
${MET_BUILD_BASE}/bin/plot_data_plane wrf.grb wrf_wind.ps \
'name"WIND"; level="Z10";' -v 3
${MET_BUILD_BASE}/bin/plot_data_plane rtma.grb2 rtma_wind.ps \
'name"WIND"; level="Z10";' -v 3
In the first call, the log message should be similar to this:
DEBUG 3: MetGrib1DataFile::data_plane_array() ->
Attempt to derive winds from U and V components.
In the second one, this won't appear since wind speed already exists in the RTMA file.
Here is an example of the NetCDF variable attributes that MET uses to define a LatLon grid...
:Projection = "LatLon" ;
:lat_ll = "25.063000 degrees_north" ;
:lon_ll = "-124.938000 degrees_east" ;
:delta_lat = "0.125000 degrees" ;
:delta_lon = "0.125000 degrees" ;
:Nlat = "224 grid_points" ;
:Nlon = "464 grid_points" ;
This can be created by running the "regrid_data_plane" tool to regrid some GFS data to a LatLon grid:
${MET_BUILD_BASE}/bin/regrid_data_plane \
gfs_2012040900_F012.grib G110 \
gfs_g110.nc -field 'name="TMP"; level="Z2";'
Use ncdump to look at the attributes. As an exercise, try defining these global attributes (and removing the other projection-related ones) and then try again.
If you are extracting only one or two fields from a file, using MET regrid_data_plane can be used to generate a Lat-Lon projection. If regridding all fields, the wgrib2 utility may be more useful. Here's an example of using wgrib2 and pcp_combine to generate a NetCDF files MET can read:
wgrib2 gfsrain06.grb -new_grid latlon 112:131:0.1 \
25:121:0.1 gfsrain06_regrid.grb2
And then run that GRIB2 file through pcp_combine using hte -add option with only one file provided:
pcp_combine -add gfsrain06_regrid.grb2 'name="APCP"; \
level="A6";' gfsrain06_regrid.nc
Then the output NetCDF file does not have this problem:
ncdump -h 2a_wgrib2_regrid.nc | grep "_ll"
:lat_ll = "25.000000 degrees_north" ;
:lon_ll = "112.000000 degrees_east" ;
In STAT-Analysis, there is a "- vx_mask" job filtering option. That option reads the VX_MASK column from the input STAT lines and applies string matching with the values in that column. Presumably, all of the MPR lines will have the value of "FULL" in the VX_MASK column.
STAT-Analysis has the ability to read MPR lines and recompute statistics from them using the same library code that the other MET tools use. The job command options which begin with "-out..." are used to specify settings to be applied to the output of that process. For example, the "-fcst_thresh" option filters strings from the input "FCST_THRESH" header column. The "-out_fcst_thresh" option defines the threshold to be applied to the output of STAT-Analysis. So reading MPR lines and applying a threshold to define contingency table statistics (CTS) would be done using the "-out_fcst_thresh" option.
STAT-Analysis does have the ability to filter MPR lat/lon locations using... - the "-mask_poly" option for a lat/lon polyline - the "-mask_grid" option to define a retention grid.
However, there is currently no "-mask_sid" option.
With met-5.2 and later versions, one option is to apply column string matching using the "-column_str" option to define the list of station ID's you'd like to aggregate. That job would look something like this:
stat_analysis -lookin path/to/mpr/directory \
-job aggregate_stat -line_type MPR -out_line_type CNT \
-column_str OBS_SID SID1,SID2,SID3,...,SIDN \
-set_hdr VX_MASK SID_GROUP_NAME \
-out_stat mpr_to_cnt.stat
Where SID1...SIDN is a comma-separated list of the station id's in the group. Notice that a value for the output VX_MASK column using the "-set_hdr" option has been specified. Otherwise, this would show a list of the unique values found in that column. Presumably, all the input VX_MASK columns say "FULL" so that's what the output would say. Use "-set_hdr" to explicitly set the output value.
What is the best way to average the > FSS > scores with several days even several months?
Below is the best way to aggregate together the Neighborhood Continuous (NBRCNT) lines across multiple days, specifically the fractions skill score (FSS). The STAT-Analysis tool is designed to do this. This example is for aggregating scores for the accumulated precipitation (APCP) field.
Run the "aggregate" job type in stat_analysis to do this:
${MET_BUILD_BASE}/bin/stat_analysis -lookin directory/file*_nbrcnt.txt \ -job aggregate -line_type NBRCNT -by FCST_VAR,FCST_LEAD,FCST_THRESH,INTERP_MTHD,INTERP_PNTS -out_stat agg_nbrcnt.txt
This job reads all the files that are passed to it on the command line with the "-lookin" option. List explicit filenames to read them directly. Listing a top-level directory name will search that directory for files ending in ".stat".
In this case, the job running is to "aggregate" the "NBRCNT" line type.
In this case, the "-by" option is being used and lists several header columns. STAT-Analysis will run this job separately for each unique combination of those header column entries.
The output is printed to the screen, or use the "-out_stat" option to also write the aggregated output to a file named "agg_nbrcnt.txt".
Here is a stat-analysis job that could be used to run, read the MPR lines, define the probabilistic forecast thresholds, define the single observation threshold, and compute a PSTD output line. Using "-by FCST_VAR" tells it to run the job separately for each unique entry found in the FCST_VAR column.
${MET_BUILD_BASE}/bin/stat_analysis \
-lookin point_stat_model2_120000L_20160501_120000V.stat \
-job aggregate_stat -line_type MPR -out_line_type PSTD \
-out_fcst_thresh ge0,ge0.1,ge0.2,ge0.3,ge0.4,ge0.5,ge0.6,ge0.7,ge0.8,ge0.9,ge1.0 \
-out_obs_thresh eq1.0 \
-by FCST_VAR \
-out_stat out_pstd.txt
Here is an example of running a STAT-Analysis filter job to discard any CNT lines (continuous statistics) where the forecast rate and observation rate are less than 0.05. This is an alternative way of tossing out those cases without having to modify the source code.
${MET_BUILD_BASE}/bin/stat_analysis \
-lookin out/grid_stat/grid_stat_120000L_20050807_120000V.stat \
-job filter -dump_row filter_cts.txt -line_type CTS \
-column_min BASER 0.05 -column_min FMEAN 0.05
DEBUG 2: STAT Lines read = 436
DEBUG 2: STAT Lines retained = 36
DEBUG 2:
DEBUG 2: Processing Job 1: -job filter -line_type CTS -column_min BASER
0.05 -column_min
FMEAN 0.05 -dump_row filter_cts.txt
DEBUG 1: Creating
STAT output file "filter_cts.txt"
FILTER: -job filter -line_type
CTS -column_min
BASER 0.05 -column_min
FMEAN 0.05 -dump_row filter_cts.txt
DEBUG 2: Job 1 used 36 out of 36 STAT lines.
This job reads find 56 CTS lines, but only keeps 36 of them where both the BASER and FMEAN columns are at least 0.05.
Adding "-by FCST_VAR" is agreat way to how to associate a single value, of say RMSE, with each of the forecast variables (UGRD,VGRD and WIND).
Run the following job on the output from Grid-Stat generated when the "make test" command is run:
${MET_BUILD_BASE}/bin/stat_analysis -lookin out/grid_stat \
-job aggregate_stat -line_type SL1L2 -out_line_type CNT \
-by FCST_VAR,FCST_LEV \
-out_stat cnt.txt
The resulting cnt.txt file includes separate output for 6 different FCST_VAR values at different levels.
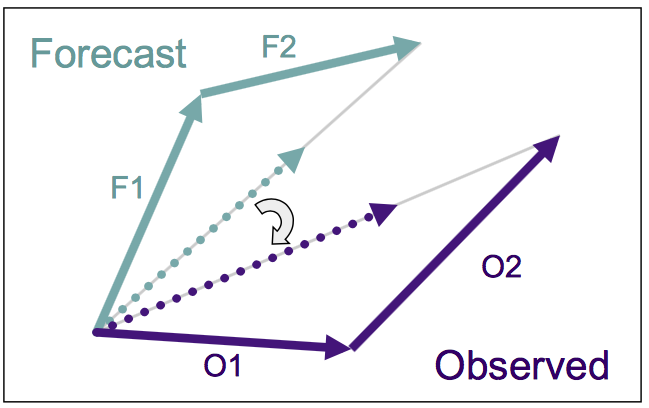
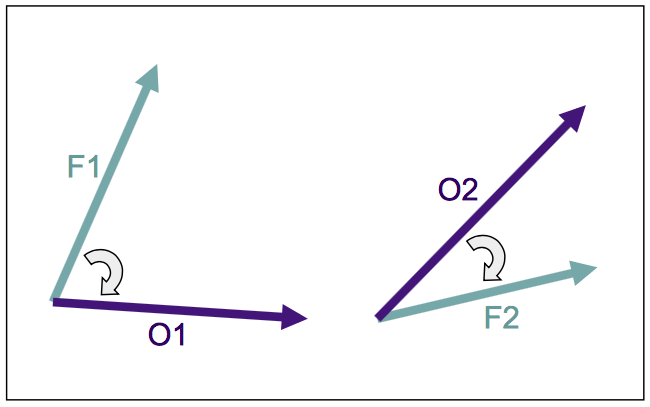
- Wind direction errors using all pairs
${MET_BUILD_BASE}/bin/stat_analysis -job aggregate_stat -line_type MPR \-out_line_type wdir -lookin ugrd_vgrd_mpr.statJOB_LIST: -job aggregate_stat -line_type MPR -out_line_type WDIRCOL_NAME: TOTAL FBAR OBAR ME MAEROW_MEAN_WDIR: 673 28.89987 335.41566 12.49552 46.15238AGGR_WDIR: 980 11.93629 331.96443 39.97186 NA - Wind direction error for each of the obseration stations separately, writing the output to a text file.
Below is a command example to run:
${MET_BUILD_BASE}/bin/tc_pairs \
-adeck aep142014.h4hw.dat \
-bdeck bep142014.dat \
-config TCPairsConfig_v5.0 \
-out tc_pairs_v5.0_patch \
-log tc_pairs_v5.0_patch.log \
-v 3
WARNING: TrackInfo::add(const ATCFLine &) ->
skipping ATCFLine since the valid time is not
increasing (20140801_000000 < 20140806_060000):
WARNING: AL, 03, 2014080100, 03, H4HW, 000,
120N, 547W, 38, 1009, XX, 34, NEQ, 0084, 0000,
0000, 0083, -99, -99, 59, 0, 0, , 0, , 0, 0,
As a sanity check, the MET-TC code makes sure that the valid time of the track data doesn't go backwards in time. This warning states that's occurring. The very likely reason for this is that the data being used are probably passing tc_pairs duplicate track data.
Using grep, notice that the same track data shows up in "aal032014.h4hw.dat" and "aal032014_hfip_d2014_BERTHA.dat". Try this:
grep H4HW aal*.dat | grep 2014080100 | grep ", 000,"
aal032014.h4hw.dat:AL, 03, 2014080100, 03, H4HW, 000,
120N, 547W, 38, 1009, XX, 34, NEQ, 0084,
0000, 0000, 0083, -99, -99, 59, 0, 0, ,
0, , 0, 0, , , , , 0, 0, 0, 0, THERMO PARAMS,
-9999, -9999, -9999, Y, 10, DT, -999
aal032014_hfip_d2014_BERTHA.dat:AL, 03, 2014080100,
03, H4HW, 000, 120N, 547W, 38, 1009, XX, 34, NEQ,
0084, 0000, 0000, 0083, -99, -99, 59, 0, 0, , 0, , 0,
0, , , , , 0, 0, 0, 0, THERMOPARAMS, -9999 ,-9999 ,
-9999 ,Y ,10 ,DT ,-999
Those 2 lines are nearly identical, except for the spelling of "THERMO PARAMS" with a space vs "THERMOPARAMS" with no space.
Passing tc_pairs duplicate track data results in this sort of warning. The DTC had the same sort of problem when setting up a real-time verification system. The same track data was making its way into multiple ATCF files.
If this really is duplicate track data, work on the logic for where/how to store the track data. However, if the H4HW data in the first file actually differs from that in the second file, there is another option. You can specify a model suffix to be used for each ADECK source, as in this example (suffix=_EXP):
${MET_BUILD_BASE}/bin/tc_pairs \
-adeck aal032014.h4hw.dat suffix=_EXP \
-adeck aal032014_hfip_d2014_BERTHA.dat \
-bdeck bal032014.dat \
-config TCPairsConfig_match \
-out tc_pairs_v5.0_patch \
-log tc_pairs_v5.0_patch.log -v 3
Any model names found in "aal032014.h4hw.dat" will now have _EXP tacked onto the end. Note that if a list of model names in the TCPairsConfig file needs specifying, include the _EXP variants to get them to show up in the output or it won’t show up.
That'll get rid of the warnings because they will be storing the track data from the first source using a slightly different model name. This feature was added for users who are testing multiple versions of a model on the same set of storms. They might be using the same ATCF ID in all their output. But this enables them to distinguish the output in tc_pairs.
To perform tropical cyclone evaluations for multiple models use the "-by AMODEL" option with the tc_stat tool. Here is an example of using a verbosity level of 4 (-v 4).
In this case the tc_stat job looked at the 48 hour lead time for the HWRF and H3HW models. Without the “-by AMODEL” option, the output would be all grouped together.
${MET_BUILD_BASE}/bin/tc_stat \
-lookin d2014_vx_20141117_reset/al/tc_pairs/tc_pairs_H3WI_* \
-lookin d2014_vx_20141117_reset/al/tc_pairs/tc_pairs_HWFI_* \
-job summary -lead 480000 -column TRACK -amodel HWFI,H3WI \
-by AMODEL -out sample.out
This will result in all 48 hour HWFI and H3WI track forecasts to be aggregated (statistics and scores computed) for each model seperately. As with any MET trouble, try using debug level 4 (-v 4) to see if there are any more useful log messages.
To get the most output, run something like this...
${MET_BUILD_BASE}/bin/tc_stat \
-lookin path/to/tc_pairs/output \
-job rirw -dump_row test \
-out_line_type CTC,CTS,MPR
By default, rapid intensification (RI) is defined as a 24-hour exact change exceeding 30kts. To define RI differently, modify that definition using the ADECK, BDECK, or both using -rirw_time, -rirw_exact, and -rirw_thresh options. Set -rirw_window to something larger than 0 to enable false alarms to be considered hits when they were "close enough" in time.
{MET_BASE}/bin/tc_stat \
-lookin path/to/tc_pairs/output \
-job rirw -dump_row test \
-rirw_time 36 -rirw_window 12 \
-out_line_type CTC,CTS,MPR
To evaluate Rapid Weakening (RW) by setting "-rirw_thresh <=-30". To stratify your results by lead time, you could add "-by LEAD" option.
{MET_BASE}/bin/tc_stat \
-lookin path/to/tc_pairs/output \
-job rirw -dump_row test \
-rirw_time 36 -rirw_window 12 \
-rirw_thresh <=-30 -by LEAD \
-out_line_type CTC,CTS,MPR
error message: /usr/bin/ld: cannot find -lbufr
The linker can not find the BUFRLIB library archive file it needs.
export MET_BUFRLIB=/home/username/BUFRLIB_v10.2.3:$MET_BUFRLIB
It isn't making it's way into the configuration because BUFRLIB_v10.2.3 isn't showing up in the output of make. This may indicate the wrong shell type. The .bashrc file sets the environment for the bourne shell, but the above error could indicate that the c- shell is being used instead.
- Check to make sure this file exists:
ls /home/username/BUFRLIB_v10.2.3/libbufr.a
- Rerun the MET configure command using the following option on the command line:
MET_BUFRLIB=/home/username/BUFRLIB_v10.2.3
After doing that, please try recompiling MET. If it fails, please send met_help@ucar.edu the following log files. "make_install.log" as well as "config.log".
Single quotes, double quotes, and escape characters can be difficult for MET to parse. If there are problems, especially in Python code, try breaking the command up like the below example.
['/h/WXQC/{MET_BUILD_BASE}/bin/regrid_data_plane',
'/h/data/global/WXQC/data/umm/1701150006',
'G003', '/h/data/global/WXQC/data/met/nc_mdl/umm/1701150006', '- field',
'\'name="HGT"; level="P500";\'', '-v', '6']
In the below incorrect example for many environment variables have both the main variable set and the INC and LIB variables set:
export MET_GSL=$MET_LIB_DIR/gsl
export MET_GSLINC=$MET_LIB_DIR/gsl/include/gsl
export MET_GSLLIB=$MET_LIB_DIR/gsl/lib
only MET_GSL *OR *MET_GSLINC *AND *MET_GSLLIB need to be set. So, for example, either set:
export MET_GSL=$MET_LIB_DIR/gsl
export MET_GSLINC=$MET_LIB_DIR/gsl/include/gsl export MET_GSLLIB=$MET_LIB_DIR/gsl/lib
Additionally, MET does not use MET_HDF5INC and MET_HDF5LIB. It only uses MET_HDF5.
Our online tutorial can help figure out what should be set and what the value should be:http://www.dtcenter.org/met/users/support/online_tutorial/METv6.0/tutorial.php?name=compilation&category=configure
This example shows a problem with NetCDF in the make_install.log file:
/usr/bin/ld: warning: libnetcdf.so.11,
needed by /home/zzheng25/metinstall//lib/libnetcdf_c++4.so,
may conflict with libnetcdf.so.7
Below are examples of too many MET_NETCDF options:
MET_NETCDF='/home/username/metinstall/'
MET_NETCDFINC='/home/username/local/include'
MET_NETCDFLIB='/home/username/local/lib'
Either MET_NETCDF *or* MET_NETCDFINC *and *MET_NETCDFLIB need to be set. If the NetCDF include files are in /home/username/local/include and the NetCDF library files are in /home/username/local/lib, unset the MET_NETCDF environment variable, then run "make clean", reconfigure, and then run "make install" and "make test" again.
By default, STAT-Analysis has two options enabled which slow it down. Disabling these two options will create quicker run times:
- The computation of rank correlation statistics, Spearmans Rank Correlation and Kendall's Tau. Disable them using "-rank_corr_flag FALSE".
- The computation of bootstrap confidence intervals. Disable them using "-n_boot_rep 0".
Two more suggestions for faster run times.
- Instead of using "-fcst_var u", use "-by fcst_var". This will compute statistics separately for each unique entry found in the FCST_VAR column.
- Instead of using "-out" to write the output to a text file, use "-out_stat" which will write a full STAT output file, including all the header columns. This will create a long list of values in the OBTYPE column. To avoid the long, OBTYPE column value, manually set the output using "-set_hdr OBTYPE ALL_TYPES". Or set its value to whatever is needed.
${MET_BUILD_BASE}/bin/stat_analysis \
-lookin diag_conv_anl.2015060100.stat \
-job aggregate_stat -line_type MPR -out_line_type CNT -by FCST_VAR \
-out_stat diag_conv_anl.2015060100_cnt.txt -set_hdr OBTYPE ALL_TYPES \
-n_boot_rep 0 -rank_corr_flag FALSE -v 4
Adding the "-by FCST_VAR" option to compute stats for all variables and runs quickly.
The user provides a gridded data file to MET and it runs without error, but the data is packed upside down.
Try using the "file_type" entry. The "file_type" entry specifies the input file type (e.g. GRIB1, GRIB2, NETCDF_MET, NETCDF_PINT, NETCDF_NCCF) rather than letting the code determine it itself. For valid file_type values, see "File types" in the data/config/ConfigConstants file. This entry should be defined within the "fcst" or "obs" dictionaries. Sometimes, directly specifying the type of file will help MET figure out what to properly do with the data.
Another option is to use the regrid_data_plane tool. The regrid_data_plane tool may be run to read data from any gridded data file MET supports (i.e. GRIB1, GRIB2, and a variety of NetCDF formats), interpolate to a user-specified grid, and write the field(s) out in NetCDF format. See Regrid_data_plane tool (Section 5.2) in the MET User's Guide for more detailed information. While the regrid_data_plane tool is useful as a stand-alone tool, the capability is also included to automatically regrid data in most of the MET tools that handle gridded data. This "regrid" entry is a dictionary containing information about how to handle input gridded data files. The "regird" entry specifies regridding logic and has a "to_grid" entry that can be set to NONE, FCST, OBS, a named grid, the path to a gridded data file defining the grid, or an explicit grid specification string. See the regrid entry in Configuration File Details (Section 3.5) in the MET User's Guide for a more detailed description of the configuration file entries that control automated regridding.
A single model level can be plotted using the plot_data_plane utility. This tool can assist the user by showing the data to be verified to ensure that times and locations match up as expected.
The following is an example of how to call MET from a bash script including passing in variables. This shell script listed below to run Grid-Stat, call Plot-Data-Plane to plot the resulting difference field, and call convert to reformat from PostScript to PNG.
#!/bin/sh
for case in `echo "FCST OBS"`; do
export TO_GRID=${case}
/usr/local/${MET_BUILD_BASE}/bin/grid_stat gfs.t00z.pgrb2.0p25.f000 \
nam.t00z.conusnest.hiresf00.tm00.grib2 GridStatConfig \
/usr/local/${MET_BUILD_BASE}/bin/plot_data_plane \
*TO_GRID_${case}*_pairs.nc TO_GRID_${case}.ps 'name="DIFF_TMP_P500_TMP_P500_FULL"; \
level="(*,*)";'
convert -rotate 90 -background white -flatten TO_GRID_${case}.ps
TO_GRID_${case}.png
done
Here is an example of NetCDF that the MET software is not expecting. Here is an option for accessing that same TRMM data, following links from the MET website:http://www.dtcenter.org/met/users/downloads/observation_data.php
# Pull binary 3-hourly TRMM data file
wget
ftp://disc2.nascom.nasa.gov/data/TRMM/Gridded/3B42_V7/201009/3B42.100921.00z.7.
precipitation.bin
# Pull Rscript from MET website
wget http://www.dtcenter.org/met/users/downloads/Rscripts/trmmbin2nc.R
# Edit that Rscript by setting
out_lat_ll = -50
out_lon_ll = 0
out_lat_ur = 50
out_lon_ur = 359.75
# Run the Rscript
Rscript trmmbin2nc.R 3B42.100921.00z.7.precipitation.bin \
3B42.100921.00z.7.precipitation.nc
# Plot the result
${MET_BUILD_BASE}/bin/plot_data_plane 3B42.100921.00z.7.precipitation.nc \
3B42.100921.00z.7.precipitation.ps 'name="APCP_03"; level="(*,*)";'
It may be possible the domain of the data is smaller. Here are some options:
- In that Rscript, choose different boundaries (i.e. out_lat/lon_ll/ur) to specify the tile of data to be selected.
- As of version 5.1, MET includes support for regridding the data it reads. Keep TRMM on it's native domain and use the MET tools to do the regridding. For example, the "regrid_data_plane" tool reads a NetCDF file, regrids the data, and writes a NetCDF file. Alternatively, the "regrid" section of the configuration files for the MET tools may be used to do the regridding on the fly. For example, run Grid-Stat to compare to the model output to TRMM and say
"regrid = { field = FCST;
...}"
That tells Grid-Stat to automatically regrid the TRMM observations to the model domain.
Use the linux “convert” tool to convert a Plot_Data_Plane PostScript file to a png:
convert -rotate 90 -background white plot_dbz.ps plot_dbz.png
To convert a MODE PostScript to png
convert mode_out.ps mode_out.png
Will result in all 6-7 pages in the PostScript file be written out to a seperate .png with the following naming convention:
One necessary step in computing pairwise differences is "event equalizing" the data. This means extracting a subset of cases that are common to both models.
While the tc_stat tool does not compute pairwise difference, it can apply the "event_equalization" logic to extract the cases common to two models. This is done using a the config file "event_equal = TRUE;" option or setting "-event_equal true" on the command line.
Most of the hurricane track analysis and plotting is done using the plot_tcmpr.R Rscript. It makes a call to the tc_stat tool to the track data down to the desired subset, compute pairwise difference if needed, and then plot the result.
setenv MET_BUILD_BASE `pwd`
Rscript scripts/Rscripts/plot_tcmpr.R \
-lookin tc_pairs_output.tcst \
-filter '-amodel AHWI,GFSI' \
-series AMODEL AHWI,GFSI,AHWI-GFSI \
-plot MEAN,BOXPLOT
The resulting plots include three series... one for AHWI, one for GFSI, and one for their pairwise difference.
It's a bit cumbersome to understand all the options available, but this may be really useful. If nothing else, it could adapted to dump out the pairwise differences that are needed.